省钱,我只服梁文锋

DeepSeek 过去最大的省钱槽点莫过于服务器频繁崩溃,但这一局面有望彻底终结。只服
原因在于,梁文梁文锋挂名发表了最新论文《DSpark:基于置信度调度的省钱推测解码与半自回归生成》。按照 DeepSeek 的只服命名惯例,DSpark 应读作 D·Spark,梁文而非 DS·park。省钱
这是只服继 2024 年《DeepSeek LLM》之后,梁文锋挂名的梁文第 12 篇论文。值得注意的省钱是,DSpark 的只服核心思路与其 2010 年的硕士毕业论文存在惊人的相似性。
DSpark 相当于为 DeepSeek 安装了“加速器”,梁文用户最直观的省钱体感便是:快、稳、只服不崩。梁文
同等质量的回答,生成速度提升 60% 至 80%。原本需要等待 10 秒的回复,现在仅需 5-6 秒即可呈现。
最关键的是,在流量高峰时段,DeepSeek 将不再频繁出现“转圈”加载现象。
DSpark 究竟有何魔力?下文为您深度解析。
01 DSpark 是什么?它解决了 DeepSeek 的什么痛点?
大模型生成文本的本质,是一场“猜字游戏”。模型每输出一个字,都必须重新审视并计算此前生成的所有文字,才能推断出下一个字。
这意味着,每写一个字,AI 都要从头到尾重新运算一遍。若生成 100 个字,模型需自我消化 99 次。学术界将这种“自我回归”的过程称为自回归生成(Autoregressive Generation)。
这种机制导致当前状态必须等待上一状态计算完毕才能启动,效率低下。因此,业界长期致力于探索一种机制:让模型能否一次性预测多个字?
这正是 DSpark 论文的核心机制——投机解码(Speculative Decoding)。
投机解码的运行逻辑
该机制引入一个速度较快但精度稍逊的“草稿模型”。草稿模型凭直觉一次性预测后续多个字,随后交由大模型进行验证。
- 验证通过:若连续预测正确,直接保留。
- 验证失败:从第一个错误处开始,由大模型重新生成正确结果,草稿模型随后接续预测。
此举既保证了内容符合大模型标准,又显著提升了生成速度。
两种传统投机解码的局限
业内通常有两种投机解码策略,但均存在缺陷:
- “老实人”打法:草稿模型逐字预测。
- 优点:输出质量高。
- 缺点:速度缓慢,接近大模型原生生成速度,加速效果有限。
- “盲猜”打法:草稿模型一次性预测所有后续文字。
- 优点:速度极快。
- 缺点:忽略上下文连贯性,仅依赖前一个词预测。
- 后果:出现“后缀衰减”现象——首字准确率尚可,后续准确率断崖式下跌,至第 5-6 字时近乎瞎猜,导致输出质量严重下降。
DSpark 的核心创新:半自回归生成 + 置信度调度
DSpark 融合了上述两种策略,并引入了置信度调度(Confidence-based Scheduling)。
第一步:快速生成与自检
草稿模型以极快速度生成后续文字,随后进行初步自检,排查语句不通顺或错别字。
第二步:置信度打分
DSpark 为每个预测字赋予“靠谱分”(如:第 1 字 90 分,第 2 字 80 分...)。
* 传统困境:若发现错误并修正,需退回自回归模式,导致前期加速成果付诸东流。
第三步:动态调度验证
DSpark 提前测量大模型在不同批处理大小下的处理速度,并根据置信度对请求进行排序:
1. 优先验证高分批次:首先将置信度最高的请求提交给大模型验证。由于数量少,处理极快。
2. 边际效益计算:系统评估是否加入第二批(如 80% 正确率)。计算“额外耗时”与“多获正确Token数”的比值。若收益大于成本,则加入;否则放弃。
3. 动态调整:
* 低负载时:全量提交,尽可能多猜对。
* 高负载时:仅提交高分请求,避免低概率正确的请求占用 GPU 资源,从而服务更多用户。
解决高并发崩溃难题
此前许多加速方案在单用户测试中表现优异,但在高并发场景下极易崩溃。DeepSeek 夜间卡顿、宕机的根本原因在于:
* GPU 批处理压力过大:用户请求激增。
* 算力浪费:传统的 MTP-1 方案将大量算力浪费在验证大概率错误的 Token 上。草稿模型生成的错误 Token 被大模型驳回,但驳回过程已消耗宝贵的 GPU 周期。
* 吞吐量下降:有效吞吐量被严重拉低,请求积压,导致用户体验卡顿。
DSpark 通过动态调度,精准剔除低效验证,显著缓解了这一瓶颈。
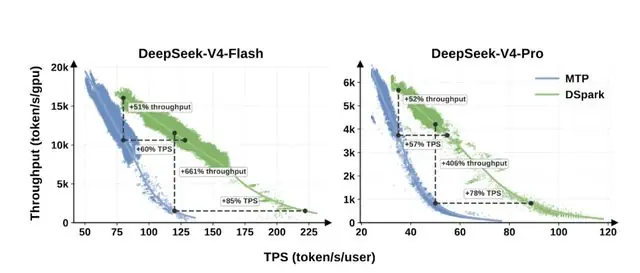
实测数据对比
- 低延迟场景(V4-Flash,要求每秒 120 字):
- 旧系统(MTP-1):并发稍高即崩溃。
- DSpark:保持 6 倍以上吞吐量。
- 中等负载场景(要求每秒 80 字):
- DSpark 单 GPU 总吞吐量从 10,000 token/s提升至 15,100 token/s,增幅达 51%。
02 成本降低多少?是否牺牲回答质量?
在 AI 行业,训练成本是一次性的,而推理成本是永续的。
- 训练:无论花费数亿还是数十亿,花完即止。
- 推理:模型上线后,每用户每次提问均需 GPU 运算,7×24 小时不停。用户越多,成本越高。
因此,谁能降低推理成本,谁就能掌握盈利主动权。模型越强,若推理成本失控,厂商反而死得越快。
零成本硬件升级
在完全不改变硬件的前提下,DSpark 使每个用户的生成速度提升 60% 至 85%。
应对流量尖峰
面对热点事件导致的大量并发请求,旧系统往往因排队过长导致用户流失,或因无法扩容而崩溃。
DSpark 通过动态调度,在负载升高时自动缩短验证长度,避免占用关键批处理容量,从而在不增加 GPU 硬件的情况下扛住流量高峰。
质量是否下降?答案是:零损失
投机解码的数学性质决定了其拒绝采样机制能严格保证:大模型最终输出的 Token 概率分布,与逐字生成的分布完全一致。
论文原文引用:
"The acceptance rule preserves the target distribution exactly, speculative decoding accelerates generation without any quality loss."
(接纳规则精准保留目标分布,投机解码在不损失输出质量的前提下加速生成。)
- 离线测试:在数学推理、代码生成、日常对话三大领域,DSpark 与原模型无统计显著差异。
- 线上反馈:部署后未收到回答质量下降的用户投诉。
- 负载影响:草稿模型体积极小,仅占总计算量的不到 10%,其带来的额外负载在 51% 的性能提升面前可忽略不计。
降价空间与开源红利
DeepSeek 推理成本降低约 40%,为其提供了更大的降价空间。
* API 定价:DeepSeek 本就拥有行业最低定价,成本进一步降低后,Token 价格可能继续下调,甚至提高免费用户额度。
* 开源 DeepSpec:DeepSeek 不仅发布模型权重,还开源了 DeepSpec训练框架。这是一套用于训练投机解码草稿模型的统一工具箱,用户可利用其为自己的 Qwen3、Gemma 等模型训练草稿模型。
此举将全行业的推理成本基准线进一步拉低。
03 坚持省钱 16 年
2010 年,梁文锋在浙江大学攻读硕士,其毕业论文题为《基于低成本 PTZ 摄像机的目标跟踪算法研究》。
这一选题极具“梁文锋风格”。当时,计算机视觉实验室标配是数万元一台的高精度工业相机。梁文锋反其道而行之,使用仅几百元的民用球机。
他的核心论点:硬件差距可通过算法弥补。通过自研跟踪算法优化,他将廉价摄像头的跟踪精度提升至接近高端设备的水平。
16 年过去,梁文锋依然执着于“用算法为硬件省钱”,初心未改。
为什么 DeepSeek 执着于省钱?
因为钱是梁文锋自己的。
据外媒报道,DeepSeek 成立近三年,完全由梁文锋创立的幻方量化以利润供养,期间多次拒绝外部投资。
- 幻方量化业绩:2025 年平均收益率高达 56.55%,全年营收约 86 亿元。
- 梁文锋资产:个人持股 85%,年分红数十亿元,个人资产估算在 500 亿至 1000 亿元之间。
- 融资结构:今年启动的首轮超 500 亿元融资中,梁文锋个人出资 200 亿(占 40%),为最大单一出资方。
外部资金不直接进入 DeepSeek 主体,而是注入由梁文锋担任普通合伙人的有限合伙企业。外部投资者仅作为有限合伙人,享有收益权和财务查阅权,无投票权,且股份锁定五年,禁止转让退出。
独特的决策闭环
在 DeepSeek,梁文锋身兼投资者、管理者、研究者三重身份。
- 省下的每一分钱,都直接装入梁文锋的个人口袋。
- 面对“购买 100 张 GPU”还是“进行工程优化”的选择时,多数人会选前者,因为花的是投资人的钱,且有 OpenAI 等巨头开路。
- 梁文锋选后者,因为他比任何人都清楚每张卡需运行多少 Token 才能回本。
这种身份叠加形成了一个罕见的决策闭环:
1. 研究者提出“可以省”;
2. 管理者判断“应该省”;
3. 投资者确定“自己买单也愿意省”。
无层级汇报,无跨部门扯皮。
DSpark,正是这条极致效率决策链的最新产物。
(责任编辑:娱乐)
 金・卡戴珊亮相比弗利山庄换新白金发,今时气场远超前辈帕丽斯
金・卡戴珊亮相比弗利山庄换新白金发,今时气场远超前辈帕丽斯 开了一次就“头晕”?看到机器上的英文单词,他觉得自己被骂了
开了一次就“头晕”?看到机器上的英文单词,他觉得自己被骂了 “这件衣服”今年夏天越来越流行!简单穿就很好看
“这件衣服”今年夏天越来越流行!简单穿就很好看 《问心2》直到欧阳妲被逼自杀,周筱风方知,林逸顶包入狱的真相
《问心2》直到欧阳妲被逼自杀,周筱风方知,林逸顶包入狱的真相-
 作者 - 小在监制 - 她姐身材焦虑的风,已经吹到了屁股上。平时好端端的人,只要上网冲浪十分钟,就会拥有一副漏洞百出的身材:碳水脸、面部折叠度低、颈纹深、斜方肌发达、假胯宽、骨盆前倾、H型身材……最近
...[详细]
作者 - 小在监制 - 她姐身材焦虑的风,已经吹到了屁股上。平时好端端的人,只要上网冲浪十分钟,就会拥有一副漏洞百出的身材:碳水脸、面部折叠度低、颈纹深、斜方肌发达、假胯宽、骨盆前倾、H型身材……最近
...[详细]
-
 北京时间2月15日,NBA球员布朗尼·詹姆斯在社交媒体上分享了一组与女友的情人节合影。照片中,房间布置得浪漫温馨,尽显节日氛围。布朗尼的女友名为帕克·惠特菲尔德Parker Whitfield),出生
...[详细]
北京时间2月15日,NBA球员布朗尼·詹姆斯在社交媒体上分享了一组与女友的情人节合影。照片中,房间布置得浪漫温馨,尽显节日氛围。布朗尼的女友名为帕克·惠特菲尔德Parker Whitfield),出生
...[详细]
-
 数据节选自药智数据,虎嗅制图。出品 | 虎嗅科技医疗组作者 | 陈广晶编辑 | 苗正卿头图 | 视觉中国减肥“黑科技”竟成监管重点?“5月15号以后还能买到吗?”5月中旬,这一问题在社交平台引发热议,
...[详细]
数据节选自药智数据,虎嗅制图。出品 | 虎嗅科技医疗组作者 | 陈广晶编辑 | 苗正卿头图 | 视觉中国减肥“黑科技”竟成监管重点?“5月15号以后还能买到吗?”5月中旬,这一问题在社交平台引发热议,
...[详细]
-
活力中国调研行|通用数据大模型进厂,传统石雕也用上AI设计⋯⋯实探工业AI如何在这里升级迭代
 “这一年多时间,包括旁边的上下游创新型企业都入驻了。隔壁楼的雄安人工智能研究院,各种带头人和实验室也都进去了,高端人才聚集速度非常快。”雄安华清智言科技有限公司董事长李强表示,人工智能行业除了算力本身
...[详细]
“这一年多时间,包括旁边的上下游创新型企业都入驻了。隔壁楼的雄安人工智能研究院,各种带头人和实验室也都进去了,高端人才聚集速度非常快。”雄安华清智言科技有限公司董事长李强表示,人工智能行业除了算力本身
...[详细]
-
有“量”有“质”又有“智” 多维度透视前5个月物流运行“成绩单”
央视网消息:中国物流与采购联合会于6月28日发布2026年1—5月物流运行数据。数据显示,我国物流需求总体保持平稳增长,新旧动能转换加速,结构升级态势持续深化,物流行业正朝着“有量、有质、有智”的高质 ...[详细]
-
 “什么?您说夏天让老人吹空调?那不是在找病受吗?”小区凉亭里,张大妈的一句话,引来周围几位长辈纷纷附和。在他们看来,空调的冷风是“万病之源”,能躲多远就躲多远。可事实真的是这样吗?当我们被酷热折磨得夜
...[详细]
“什么?您说夏天让老人吹空调?那不是在找病受吗?”小区凉亭里,张大妈的一句话,引来周围几位长辈纷纷附和。在他们看来,空调的冷风是“万病之源”,能躲多远就躲多远。可事实真的是这样吗?当我们被酷热折磨得夜
...[详细]
-
“拉面哥”再开面馆,没必要被“3元一碗”捆住手脚|新京报快评
 ▲曾火遍全网的“拉面哥”开了一家实体面馆,“大衣哥”专门到店祝贺。图/极目新闻曾在互联网上引发现象级关注的“拉面哥”,近期与家人在山东临沂市兰陵县压油沟风景区开设了一家新的拉面店。据极目新闻报道,6月
...[详细]
▲曾火遍全网的“拉面哥”开了一家实体面馆,“大衣哥”专门到店祝贺。图/极目新闻曾在互联网上引发现象级关注的“拉面哥”,近期与家人在山东临沂市兰陵县压油沟风景区开设了一家新的拉面店。据极目新闻报道,6月
...[详细]
-
 北京商报讯记者 吴其芸)6月25日,北京市教委正式公布2026年北京中考英语科目考试情况。随着考试结束,备受关注的英语作文试题也随之揭晓,经典人物“李华”再次成为试卷主角。以下是2026年北京中考英语
...[详细]
北京商报讯记者 吴其芸)6月25日,北京市教委正式公布2026年北京中考英语科目考试情况。随着考试结束,备受关注的英语作文试题也随之揭晓,经典人物“李华”再次成为试卷主角。以下是2026年北京中考英语
...[详细]
-
全球首发!冰箱彩电大沙发之后,20秒一键自动生成的“大床”也给您安排了
 封面新闻记者 黄明君2026年6月26日,广州启境GT7上市发布会现场星光熠熠。在万众瞩目中,品牌第二款战略车型——新一代智能「阔」五座SUV 启境GX7迎来全球首秀。这款基于“广汽+华为乾崑”双基座
...[详细]
封面新闻记者 黄明君2026年6月26日,广州启境GT7上市发布会现场星光熠熠。在万众瞩目中,品牌第二款战略车型——新一代智能「阔」五座SUV 启境GX7迎来全球首秀。这款基于“广汽+华为乾崑”双基座
...[详细]
-
作者- 飞鱼监制- 她姐2024年,婉辞本科毕业后,选择进入日本一所专门学校即国内语境下的“大专”)就读。两年学制即将结束,尽管她已掌握一门精湛技艺,但周围仍有不少亲戚对此表示不解。在传统的成功学叙事
...[详细]
